|
 |
|
Welcome to the world of Scilab Speech Introduction
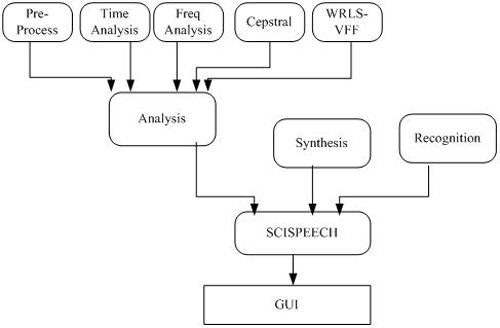
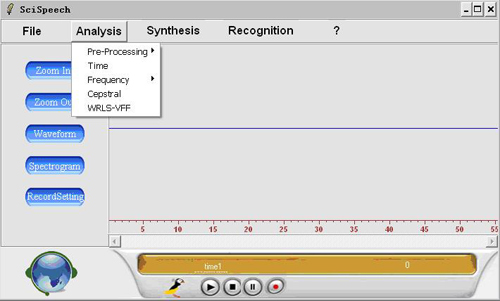
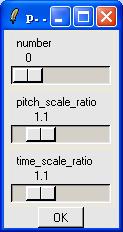
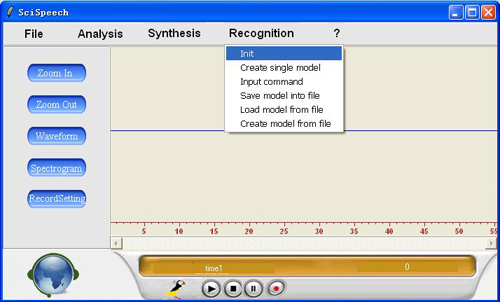
Our system can be divided into three parts: analysis, systhesis and recognition. The analysis part includes pre-processing, time analysis, frequency analysis, cepstral analysis and WRLS-VFF analysis, it can analyse the characteristic of speech from many aspects, which means its function is perfect. In the synthesis part, you can change the pitch frequency and time scale ratio freely to adjust the prosodics. In the recognition part, we implement a talker-dependent, isolated-word recognition system. The users can also create their own models. |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Copyright (C) 2006-2007 Scilab group of Xiamen University, China |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
 |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||