Developer's Guide--Part I
Pre-emphasis
enframe and windowing
Pre-emphasis
In common narrowband two way fm communications, Pre emphasis follows a 6 dB per octave rate. This means that as the frequency doubles, the amplitude increases 6 dB. Pre emphasis is needed in FM to maintain good signal to noise ratio. Why is it necessary? Common voice characteristics emit low frequencies higher in amplitude than high frequencies. The limiter circuits that clip the voice to allow protection of over deviation are usually not frequency sensitive, and are fixed in level, so they will clip or limit the lows before the highs. This results in added distortion because of the lows overdriving the limiter. Pre emphasis is used to shape the voice signals to create a more equal amplitude of lows and highs before their application to the limiter. The result is that the signal received is perceived louder due to more equal clipping or limiting of the signal, but probably more important is the increased level of the higher frequencies being applied to the modulator results in a better transmitted audio signal to noise ratio due to the highs being above the noise as much or more than the lows.
back to top
enframe and windowing
After Pre-emphasis by digital filter, what we should do is enframe and windowing. Compared to the speed of sound wave vibration, the movement of pronunciation organ is too slowly. In this situation, engineering technicians assume that speech signal is steady within 10ms~30ms times. Almost all the speech processing method is based on this assumption. As a result, there are 33~100 frames every second. We use overlap added method in most of the time, so it can transfer from one frame to anther smoothly.
The time-windowing process is illustrated in Fig. 1 .
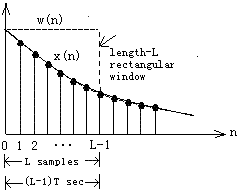 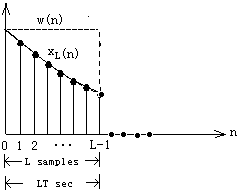
Fig. 1 . Time windowing
In terms of the time samples 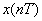 , the original sampled spectrum , the original sampled spectrum 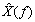 and its time-windowed version and its time-windowed version 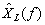 are given by: are given by:
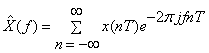
(1.2.1)
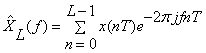
As seen in Fig. 1 , the duration of the windowed data record from the time sample at n=0 to the sample at n=L-1 is (L-1)T seconds, where T is the sampling time interval 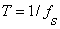 . Because each sample lasts for T seconds, the last sample will last until time LT. Therefore, we may take the duration of the data record to be . Because each sample lasts for T seconds, the last sample will last until time LT. Therefore, we may take the duration of the data record to be 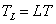 . .
The windowed signal may be thought of as an infinite signal which is zero outside the range of the window and agrees with the original one within the window. To express this mathematically, we define the rectangular window of length L :
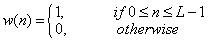
Then, define the windowed signal as follows:
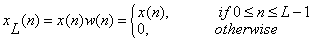
The multiplication by 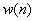 ensures that ensures that 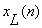 vanish outside the window. Equation(1.2.1) can now be expressed more simply in the form: vanish outside the window. Equation(1.2.1) can now be expressed more simply in the form:
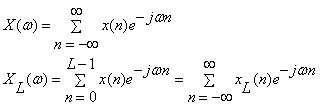
where 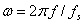 . Thus, . Thus, 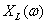 is the DTFT of the windowed signal is the DTFT of the windowed signal 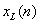 and is computable for any desired value of and is computable for any desired value of 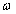 . .
The windowing function that we always use in the speech processing is the Rectangular Window and the Hamming Window , the Hamming Window can be defined as follows:
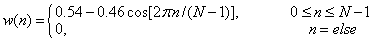
In the time domain analysis, the window type and the window length can influence the result directly.
back to top |



