Welcome to the world of Scilab Speech
System Requirement
Installment
Speech Analysis
Speech Synthesis
Speech Recognition
1. System Requirement:
Scilab Speech can work with any computer that has Scilab-4.0. Its interface is written in tcl/tk. We have Windows version and Linux version, which can run separately under Windows and Linux. (For some reason, Linux version is not perfect, so Windows version is strongly recommended).
back to top
2. Installment
1) Windows version
We have done all the things for you(Windows Version). You only need to install Scilab Speech under the Scilab directory, then it will generate two shortcuts in desktop. One is for GUI and the other is for Command-Line. Double click it you can do all the operations supported by us.
After installation, 2 shortcut icons will be created on the desktop:
Please make that SciSpeech is installed under the directory of scilab-4.0, otherwise the software won't work correctly.
 :start SciSpeech in the mode of GUI. :start SciSpeech in the mode of GUI.
 : start SciSpeech in the mode of Command-Line. : start SciSpeech in the mode of Command-Line.
2) Linux version
1. install Scilab-4.0 first.
2. copy SciSpeech and start.sci to the installed directory of Scilab-4.0.
Please make sure all the file of SciSpeech has been copied under the directory of scilab-4.0, otherwise the software won't work correctly.
3. execute Scilab, load start.sci into Scilab.
back to top
3. Interface Preview
GUI--Main Window:
The follow pictures show the main function.
Analysis:
Please load an audio file by using File-->Open first.
Pre-processing:
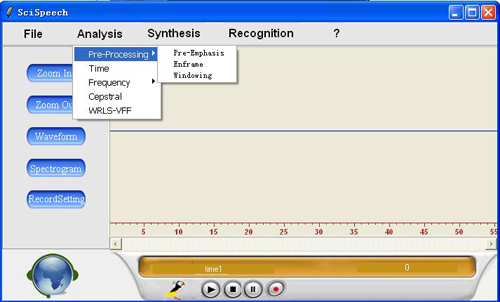
Pre-Emphasis
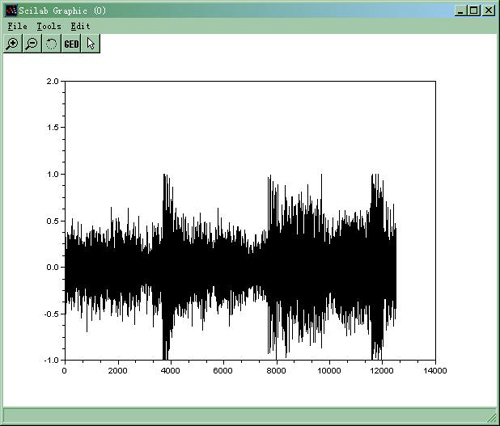
Please load an audio by using File-->Open first, and then select "Pre-Processing-->Pre-Emphasis".(For some reasons, in this process you can only load "SciSpeech\doc\sample.wav").
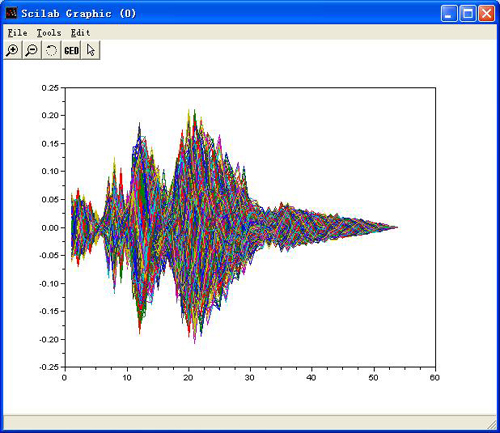
Enframe----split speech signal into frames:
Please load an audio by using File-->Open first, and then select "Pre-Processing-->Enframe"
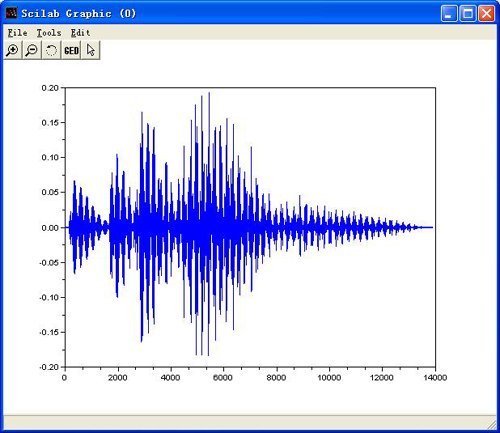
windowing:
Please load an audio by using File-->Open first, and then select "Pre-Processing-->Windowing"
Time:
energy----the short time energy:
Please load an audio by using File-->Open first, and then select "Time-->energy"
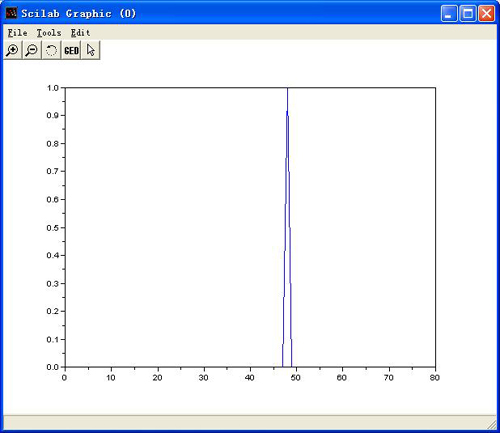
zcr----the zero crossing rate:
Please load an audio by using File-->Open first, and then select "Time-->zcr"
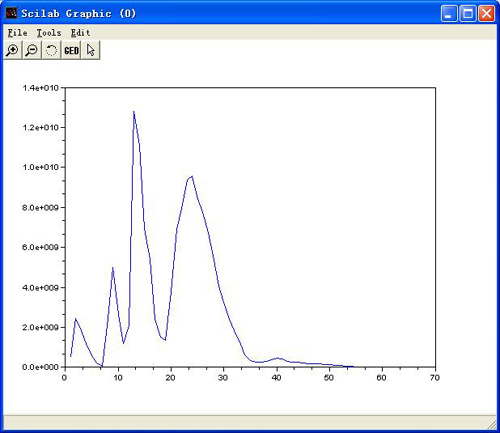
LP analysis----Linear Prediction analysis:
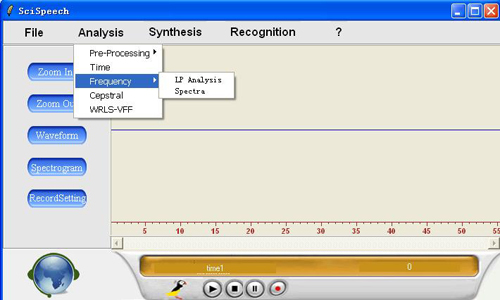
Please load an audio by using File-->Open first, and then select "Frequency-->LP Analysis "
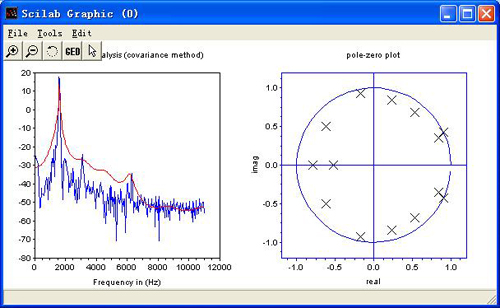
spectra----spectral estimation:
Please load an audio by using File-->Open first, and then select "Frequency-->Spectra"
cepstral----cepstral analysis:
Please load an audio by using File-->Open first, and then select "Cepstral"
WRLS-VFF----the WRLS-VFF analysis:
Please load an audio by using File-->Open first, and then select "WRLS-VFF"
back to top
Synthesis:
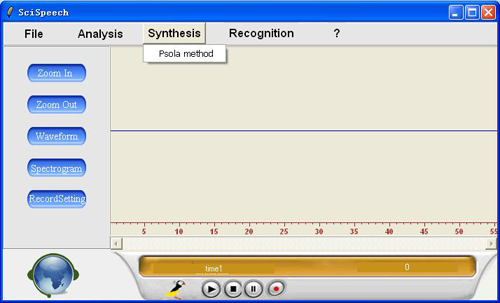
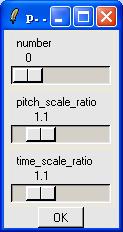
We have the pronunciation of 10 numbers from 0~9, you can select the number by using the first scorll bar. And you can also adjust the prosodics by changing the following two parameters, one of the is pitch frequency, labeled "pitch_scale_ratio". The other one is time scale ratio, labeled "time_scale_ratio". For example, if both the "pitch_scale_ratio" and the "time_scale_ratio" are 1, then it is the original speech signal.
back to top
Recognition:
Do you want to recognize the telephone number that you record by using our software? And shut down or restart computer? Please do as follows:
1. Select "Init", init data.
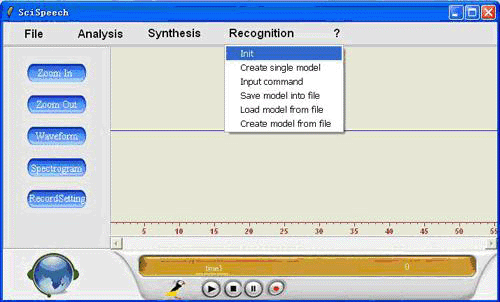
2. This recognition system is a talker-dependent recognition system, please create your own model first so that our system can recognize you command.
For example, Click "Create Single Model", input "0" in the textbox, and click Record, then record "zero" and click "stop", finally click "ok".
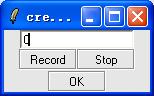
3. input "1" in the textbox, do as what described in the step 2 until creat the model of number 0-9.
4. Select "Input command"
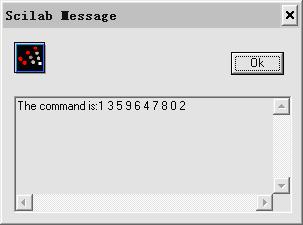
Click "Record" to record the speech command, For example, record "1359647802". Please note that our system is isolated-word recognition system, so here we require you stop about half a second between every number. Click "Stop" when record over.
Then click "OK", wait for a while and then the result will come out.
5. Select "Save model into file", you can save the model that has been created into .mdl file. Next time you can load the model by select "Load model from file" instead of record the number again.
If you want to shut down or restart you computer, please do as follows:
In the step 2 that described above, when you input command in the textbox, if you input the following command then you can control you computer by using our system:
text commands function
shutdown shut down the computer
logoff log off the operating system
restart restart the computer
help run scilab help
demo run SciSpeech demos
For example, select "Creat Single Model", input "demo" in the textbox and record "demo" by using microphone.
then select "Input Command" to record a speech command, if the speech command that you record include "demo", then our system will run SciSpeech demos.
Speech recognition demo:
We also provide a sample model file and speech command so that you can see the effect of speech recognition conveniently.
demo1:
1. Select "Init" to init data.
2. Select "Load model from file", and select "SciSpeech\function\a\wucong\wucong.mdl", this file is created by wucong. Please note that our system is talker-dependent recognition system, the model created by wucong can only correspond to the command record by wucong.
3. Select "Input command". Click "Load" and select "SciSpeech\function\a\wucong\1359647802.wav", this audio file is record by wucong. Please wait for a while, then the result will come out.
demo2:
1. Select "Init" to init data.
2. Select "Creat model from file", this option will will create a model that correspond to the file 0a.wav, 1a.wav, ... , 9a.wav that under the direcotry "SciSpeech\function\a\".
3. Select "Input command", then click "Load" to load the file "SciSpeech\function\a\1374589602.wav". Wait for a while and the result will come out.
demo3:
Select "?-->Demo", click "Recognition", then out system will recognize the speech command that has been record, at last it will run scilab help.
back to top
|



