Welcome to the world of Scilab Speech
recognition demo:
Do you want to recognize the telephone number that you record by using our software? And shut down or restart computer? Please do as follows:
1. Select "Init", init data.
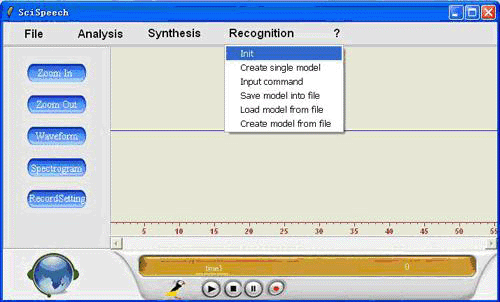
2. This recognition system is a talker-dependent recognition system, please create your own model first so that our system can recognize you command.
For example, Click "Create Single Model", input "0" in the textbox, and click Record, then record "zero" and click "stop", finally click "ok".
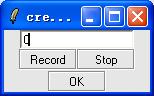
3. input "1" in the textbox, do as what described in the step 2 until creat the model of number 0-9.
4. Select "Input command"
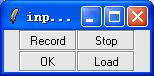
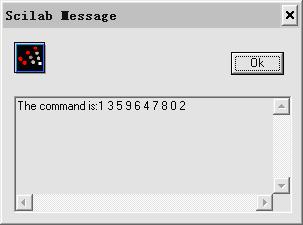
Click "Record" to record the speech command, For example, record "1359647802". Please note that our system is isolated-word recognition system, so here we require you stop about half a second between every number. Click "Stop" when record over.
Then click "OK", wait for a while and then the result will come out.
5. Select "Save model into file", you can save the model that has been created into .mdl file. Next time you can load the model by select "Load model from file" instead of record the number again.
If you want to shut down or restart you computer, please do as follows:
In the step 2 that described above, when you input command in the textbox, if you input the following command then you can control you computer by using our system:
text commands function
shutdown shut down the computer
logoff log off the operating system
restart restart the computer
help run scilab help
demo run SciSpeech demos
For example, select "Creat Single Model", input "demo" in the textbox and record "demo" by using microphone.
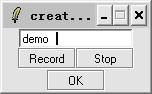
then select "Input Command" to record a speech command, if the speech command that you record include "demo", then our system will run SciSpeech demos.
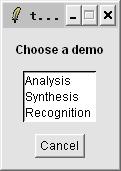
Speech recognition demo:
We also provide a sample model file and speech command so that you can see the effect of speech recognition conveniently.
demo1:
1. Select "Init" to init data.
2. Select "Load model from file", and select "SciSpeech\function\a\wucong\wucong.mdl", this file is created by wucong. Please note that our system is talker-dependent recognition system, the model created by wucong can only correspond to the command record by wucong.
3. Select "Input command". Click "Load" and select "SciSpeech\function\a\wucong\1359647802.wav", this audio file is record by wucong. Please wait for a while, then the result will come out.
demo2:
1. Select "Init" to init data.
2. Select "Creat model from file", this option will will create a model that correspond to the file 0a.wav, 1a.wav, ... , 9a.wav that under the direcotry "SciSpeech\function\a\".
3. Select "Input command", then click "Load" to load the file "SciSpeech\function\a\1374589602.wav". Wait for a while and the result will come out.
demo3:
Select "?-->Demo", click "Recognition", then out system will recognize the speech command that has been record, at last it will run scilab help. |



