欢迎使用Scilab Speech
识别效果演示:
您想实现让电脑识别您语音录入的电话号码,以及语音命令电脑关机,重启等功能么?请按以下步骤:
第一步:点击 Init, 初始化数据。
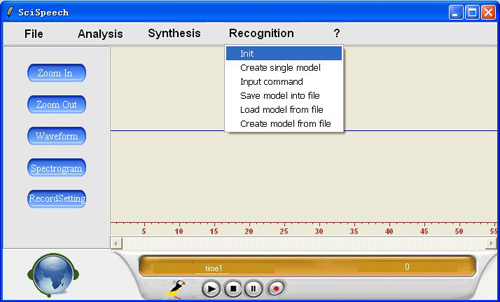
第二步:由于我们做的是特定人语音识别,请务必建立自己模版,以让计算机能够相应您的命令。点击 Create Single Model ,在文本框中输入 0 ,然后点击 Record, 对着麦克风读“ zero”.
然后点击 stop. 再点击 ok 。
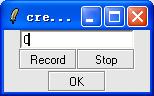
第三步:在文本框中输入 1 , 重复第二步,直到建立了 0 到 9 个数字的模版。
第四步:点击 Input command
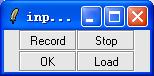
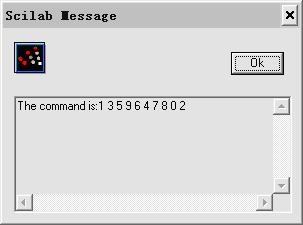
点击 Record 录入语音命令,如读入“ 1359647802 ”。由于我们所做的是孤立词识别,请在读每个数字中间空大概 0.5 秒的时间。命令录入完毕后点击 Stop.
点击 OK 键,稍后就出现结果。
第五步:点击 Save model into file, 将建立好的模版存入 .mdl 文件中。下次您可以使用 Load model from file 直接读出模版,而不用再次通过录制语音文件来创建模板。
如果您想语音命令电脑关机,重启等功能,请在第二步 Create Single Model 中训练以下文本的命令,能实现对电脑的控制。
命令文本 控制功能
shutdown 关机
logoff 注销
restart 重启
help 运行scilab帮助
demo 打开SciSpeech 范例
例: 在 Create Single Model 中,训练一个文本为 demo 的命令:

之后在 Input Command 中,如果输入有语音为 demo 的命令,则自动弹出 SciSpeech 的 demo 窗口:
语音识别范例:
我们为您提供了一系列录制好的样本和语音命令,方便为您演示语音识别的效果。
范例一:
1. 点击 Init 初始化。
2. 点击 Load model from file 选中 "Scispeech\function\a\wucong\wucong.mdl" 这是 wucong 建立的模版。 请注意本系统为特定人识别系统, wucong 建立的模版只能响应 wucong 发出的命令。
3. 点击 Input command 。然后点击 Load 键选中 "Scispeech\function\a\wucong\1359647802.wav".这是 wucong 预先录入的语音命令。稍后就会出现结果。
范例二:
1. 点击 Init 初始化。
2. 点击 Creat model from file ,这将会把 "Scispeech\function\a\" 目录下的起名为 0a .wav, 1a .wav…… 9a .wav 九个音频文件建立成模版。
3. 点击 Input command. 。然后点击 Load 键选中 "Scispeech\function\a\1374589602.wav" 。稍后就会出现结果。
范例三:
直接点击 demo 中的 Recognition ,将会将预存的一段命令识别,并且按命令弹出 help 窗口。 |



